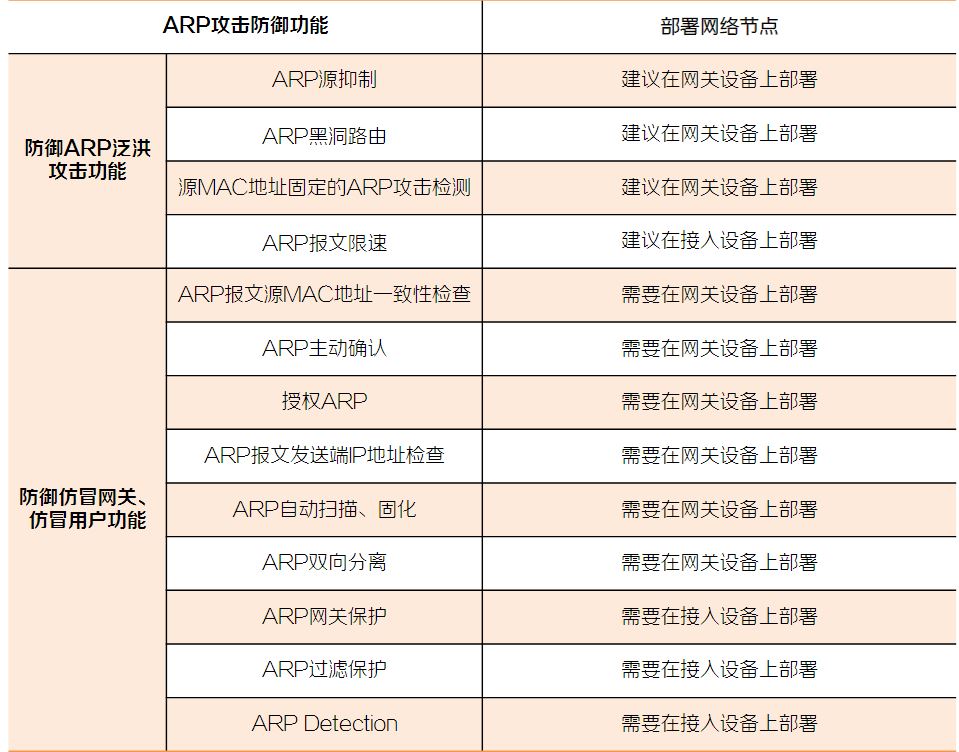
问题1:硬盘驱动器故障排除
如果系统中存在 RAID 控制器且在 RAID 阵列中配置了硬盘驱动器,则执行下列步骤:
确保已正确配置 RAID 阵列的硬盘驱动器。
将硬盘驱动器置于离线状态并重置驱动器。
退出配置公用程序并允许系统引导至操作系统。
确保已正确安装和配置控制器卡所需的设备驱动程序。
有关更多信息,请参阅操作系统说明文件。
重新启动系统并进入System Setup(系统设置)。
验证控制器是否已启用以及System Setup(系统设置)中是否显示该驱动器。
问题2:重建出现故障的物理磁盘
问题:
纠正措施:
注:您可以使用CONTROLLER BIOS配置公用程序( )或Dell OpenManage Storage Management应用程序来执行单个物理磁盘的手动重建。
问题3:Smart错误
SMART 监测所有马达、磁头和物理磁盘电子设备的内部性能并检测可预测的物理磁盘故障。
注:有关在何处查找可指示硬件故障的SMART错误报告的信息,请参阅support.dell.com/manuals上的Dell OpenManage Storage Management说明文件。
问题1:在冗余虚拟磁盘中的物理磁盘上检测到错误
问题:在冗余虚拟磁盘中的物理磁盘上检测到SMART错误。
强制物理磁盘脱机。
使用相等或更高容量的新物理磁盘更换该物理磁盘。
执行 Replace Member(更换成员)操作。
问题 2:在非冗余虚拟磁盘中的物理磁盘上检测到 Smart 错误
问题:在冗余虚拟磁盘中的物理磁盘上检测到SMART错误。
纠正措施:
使用Replace Member(更换成员)或设置全局热备件来自动更换磁盘。注:有关Replace Member(更换成员)功能的更多信息,请参阅主题”Using Replace Member and Revertible Hot Spares”(使用更换成员和可恢复热备件)。
使用相等或更高容量的新物理磁盘更换受影响的物理磁盘。
从备份进行还原。
问题4:外部配置
当存在外部配置时,可以选择 Foreign Configuration View(外部配置视图)显示配置。如果已导入外部设置,则该屏幕可将其按照原样显示。可以在决定是否导入或删除外部配置之前,预览外部配置。
注:CONTROLLER BIOS配置公用程序( )会报告外部配置导入失败的错误代码。
发现外部配置错误消息
可能原因:
纠正措施:
在 中未发现外部配置错误消息
开机自检期间出现外部配置消息,但 的外部视图页面中未出现外部配置。All virtual disks are in an optimal state.
纠正措施:
注意:清除外部配置时,物理磁盘将转为Ready(就绪)状态。
问题5:电池记忆周期/电池或内存错误
电池的透明记忆周期
注:仅在PERC H710、H710P和H810卡上支持电池。
控制器每隔90天在电池上自动执行TLC,以校准和衡量其充电容量。如果需要,此操作也可手动执行。
注:在透明记忆周期过程中,虚拟磁盘处于回写模式(如果已启用)。当 TLC 完成后,控制器将下次 TLC 设置为 90 天后。
内存或电池问题错误消息
可能原因:
适配器检测到控制器高速缓存中存在尚未写入磁盘子系统的数据。
问题6:创建虚拟磁盘
要观看6:23分钟有关创建虚拟磁盘的视频,请参阅Dell TechCenter YouTube视频:OpenManage Storage Services 7.2 – Enhancements in virtual Disk Creation Wizard(OpenManage Storage Services 7.2 – 虚拟磁盘创建向导中的增强功能)
注:不支持在一个虚拟磁盘中组合使用SAS和SATA磁盘驱动器。同样,也不支持在虚拟磁盘中组合使用磁盘驱动器和SSD。
在CONTROLLER BIOS中执行以下步骤,以创建虚拟磁盘:
< >
如果有多台控制器,则会显示Main Menu(主菜单)屏幕。
选择一个控制器,然后按键。随即显示选定控制器的 Virtual Disk Management(虚拟磁盘管理)屏幕。
使用箭头键高亮显示Controller # (控制器#)或Disk Group #(磁盘组#)。
按键。随即显示可用操作的列表。
选择Create New VD(创建新虚拟磁盘),然后按键。
< >
将虚拟磁盘添加到磁盘组时,将显示Add VD in Disk Group(在磁盘组中添加虚拟磁盘)屏幕。
跳至步骤11可更改虚拟磁盘的基本设置。
根据可用的物理磁盘,按键显示可能的RAID级别。
按向下箭头键选择RAID级别,然后按键。
当创建跨接式虚拟磁盘时(RAID 10、50 或 60),请在 PD per Span(每个跨度的物理磁盘)字段中输入每个跨度的物理磁盘数目,然后按 键。
按键将光标移动到物理磁盘列表。
使用箭头键高亮显示物理磁盘,然后按空格键、键或键选择磁盘。
如果需要,可选择其他磁盘。
按键将光标移动到Basic Settings(基本设置)框。
在VD Size(虚拟磁盘大小)字段中设置虚拟磁盘大小。虚拟磁盘大小以 GB 格式显示。
按键访问VD Name(虚拟磁盘名称)字段,然后键入虚拟磁盘名称。
按键将光标移动到Advanced Settings(高级设置)。
按空格键激活设置以便进行更改。
< >
设置有磁条元素大小、读取策略和写入策略。
您也可以选择Advanced Options(高级选项),例如,强制将高速缓存策略设置为回写、初始化虚拟磁盘和配置专用热备件。
显示默认参数。您可以接受或更改默认值。
问题7:虚拟磁盘降级
虚拟磁盘降级错误消息和纠正措施
虚拟磁盘降级错误消息
可能原因:
纠正措施:
确保虚拟磁盘中的所有磁盘均存在且处于联机状态。
更换阵列中可能存在的所有故障磁盘。
纠正热备件磁盘,重建阵列。
CONTROLLER BIOS不采取任何措施。
问题8:全局热备用
创建全局热备用
只要全局热备用的容量等于或大于故障物理磁盘的强制容量,就可以使用全局热备用替换任何冗余阵列中的故障物理磁盘。
执行以下步骤可创建全局热备用:
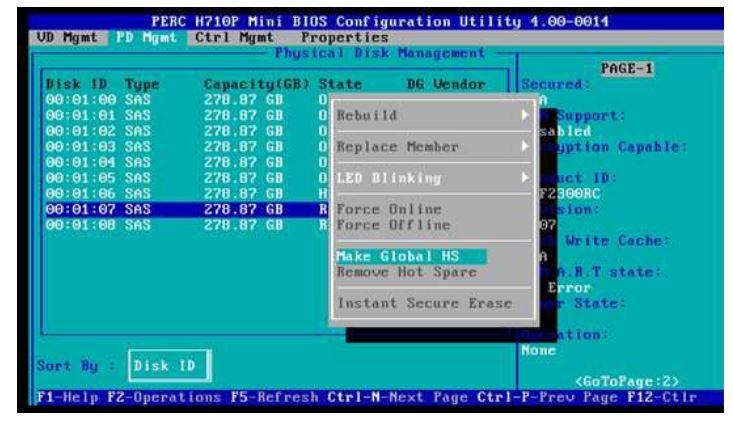
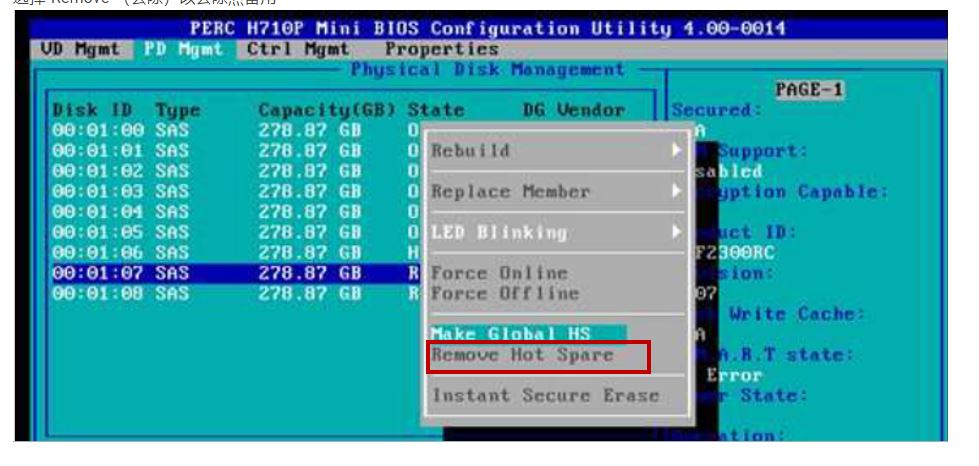
删除全局热备用或专用热备用
选择”Remove”(去除)以去除热备用
问题9:卸下和安装热插拔硬盘驱动器
卸下热交换硬盘驱动器
注意:为防止数据丢失,请确保操作系统支持热交换驱动器安装。请参阅操作系统附带的说明文件。
从硬盘驱动器托盘中卸下硬盘驱动器
将硬盘驱动器装入硬盘驱动器托盘
注意:多数修理只能由合格的维修技术人员进行。您只能根据产品说明文件中的授权,或者在联机或电话服务和支持小组的指导下,进行故障排除和简单的维修。由于未经戴尔授权的服务而导致的损坏不包括在保修范围内。请阅读并遵循产品附带的安全说明。
安装热交换硬盘驱动器
注意:多数修理只能由合格的维修技术人员进行。您只能根据产品说明文件中的授权,或者在联机或电话服务和支持小组的指导下,进行故障排除和简单的维修。由于未经戴尔授权的服务而导致的损坏不包括在保修范围内。
注意:只能使用经测试和核准可用于硬盘驱动器背板的硬盘驱动器。
注意:不支持在同一个RAID卷中组合使用SAS和SATA硬盘。
注意:安装硬盘驱动器时,请确保相邻驱动器均已完全安装到位。如果相邻的托盘未安装到位,则插入硬盘驱动器托盘且尝试锁定其旁边的手柄可能会损坏未安装到位托盘的保护弹簧,使其无法使用。
注意:为防止数据丢失,请确保操作系统支持热交换驱动器安装。请参阅操作系统附带的说明文件。
注意:在安装了更换的热插拔硬盘驱动器并且系统开机后,硬盘驱动器会自动开始重建。确保更换的硬盘为空白或包含要覆盖的数据。更换的硬盘驱动器在安装完毕后,上面的所有数据都将立即丢失。